Currently, there are 9 functions associated with the
sample verb in the sgsR package:
| Algorithm | Description | Reference |
|---|---|---|
sample_srs() |
Simple random | |
sample_systematic() |
Systematic | |
sample_strat() |
Stratified | Queinnec, White, & Coops (2021) |
sample_sys_strat() |
Systematic Stratified | |
sample_nc() |
Nearest centroid | Melville & Stone (2016) |
sample_clhs() |
Conditioned Latin hypercube | Minasny & McBratney (2006) |
sample_balanced() |
Balanced sampling | Grafström, A. Lisic, J (2018) |
sample_ahels() |
Adapted hypercube evaluation of a legacy sample | Malone, Minasny, & Brungard (2019) |
sample_existing() |
Sub-sampling an existing sample |
sample_srs
We have demonstrated a simple example of using the
sample_srs() function in vignette("sgsR"). We
will demonstrate additional examples below.
raster
The input required for sample_srs() is a
raster. This means that sraster and
mraster are supported for this function.
#--- perform simple random sampling ---#
sample_srs(
raster = sraster, # input sraster
nSamp = 200, # number of desired sample units
plot = TRUE
) # plot
#> Simple feature collection with 200 features and 0 fields
#> Geometry type: POINT
#> Dimension: XY
#> Bounding box: xmin: 431170 ymin: 5337730 xmax: 438450 ymax: 5343230
#> Projected CRS: UTM Zone 17, Northern Hemisphere
#> First 10 features:
#> geometry
#> 1 POINT (432850 5343170)
#> 2 POINT (434270 5340610)
#> 3 POINT (436270 5341990)
#> 4 POINT (436450 5340530)
#> 5 POINT (437610 5340970)
#> 6 POINT (431950 5341070)
#> 7 POINT (435610 5340970)
#> 8 POINT (431250 5341710)
#> 9 POINT (432350 5342790)
#> 10 POINT (433110 5343010)
sample_srs(
raster = mraster, # input mraster
nSamp = 200, # number of desired sample units
access = access, # define access road network
mindist = 200, # minimum distance sample units must be apart from one another
buff_inner = 50, # inner buffer - no sample units within this distance from road
buff_outer = 200, # outer buffer - no sample units further than this distance from road
plot = TRUE
) # plot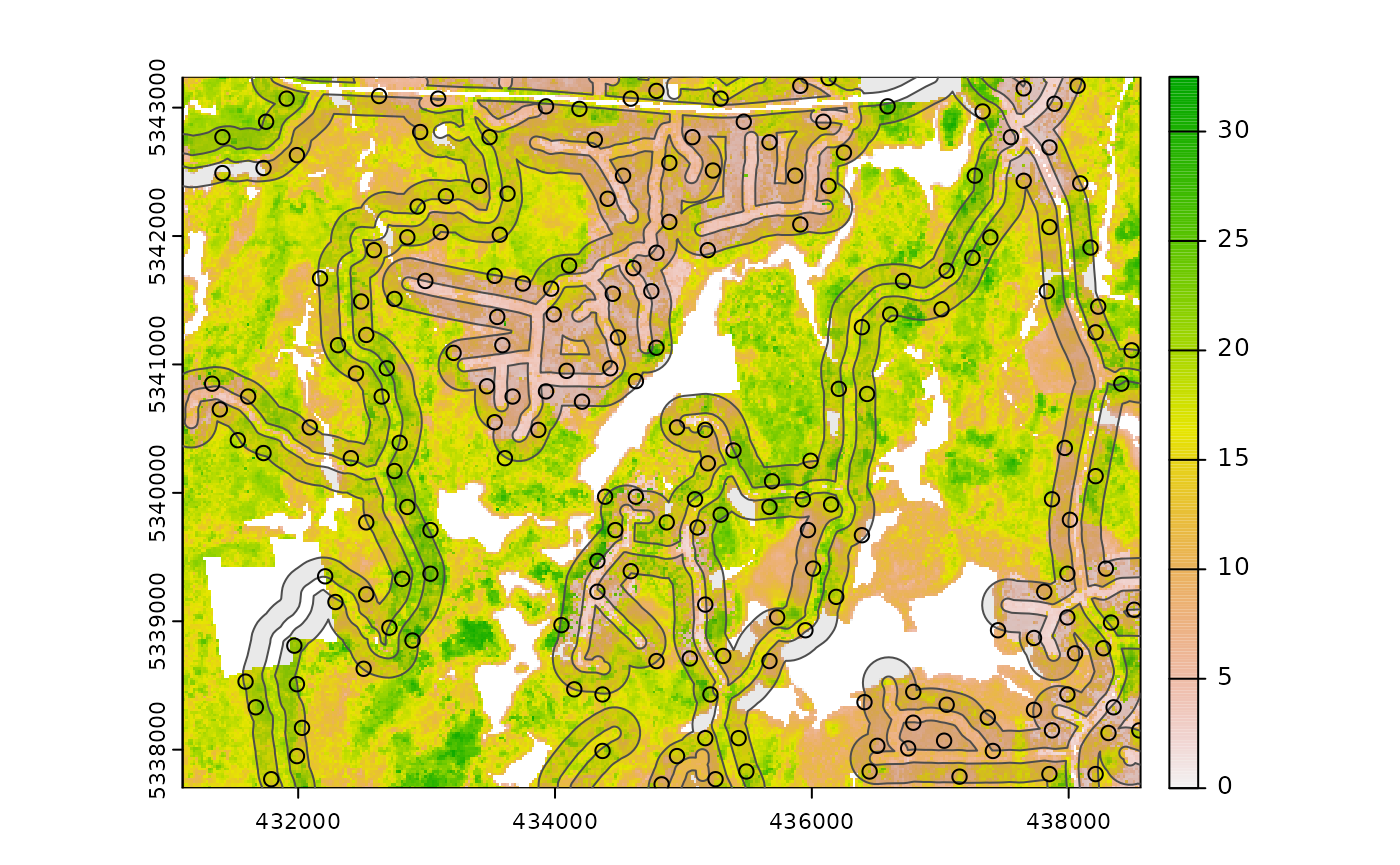
#> Simple feature collection with 200 features and 0 fields
#> Geometry type: POINT
#> Dimension: XY
#> Bounding box: xmin: 431370 ymin: 5337750 xmax: 438510 ymax: 5343230
#> Projected CRS: UTM Zone 17, Northern Hemisphere
#> First 10 features:
#> geometry
#> 1 POINT (434690 5339670)
#> 2 POINT (433810 5340350)
#> 3 POINT (433330 5342430)
#> 4 POINT (437150 5342230)
#> 5 POINT (436830 5338030)
#> 6 POINT (432930 5341990)
#> 7 POINT (434810 5342050)
#> 8 POINT (434170 5342950)
#> 9 POINT (432650 5340410)
#> 10 POINT (435870 5340070)
sample_systematic
The sample_systematic() function applies systematic
sampling across an area with the cellsize parameter
defining the resolution of the tessellation. The tessellation shape can
be modified using the square parameter. Assigning
TRUE (default) to the square parameter results
in a regular grid and assigning FALSE results in a
hexagonal grid.
The location of sample units can also be adjusted using the
locations parameter, where centers takes the
center, corners takes all corners, and random
takes a random location within each tessellation. Random start points
and translations are applied when the function is called.
#--- perform grid sampling ---#
sample_systematic(
raster = sraster, # input sraster
cellsize = 1000, # grid distance
plot = TRUE
) # plot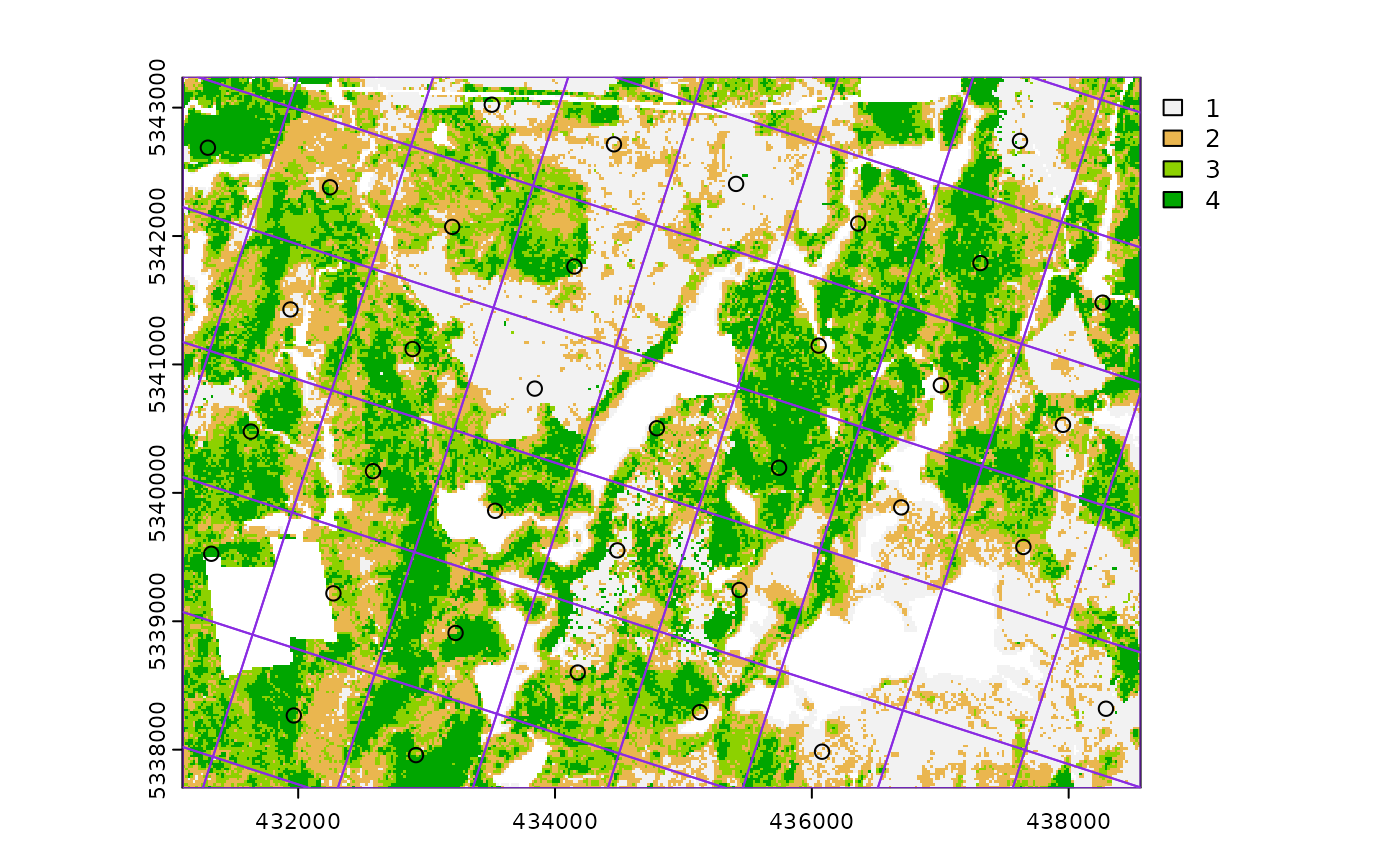
#> Simple feature collection with 36 features and 0 fields
#> Geometry type: POINT
#> Dimension: XY
#> Bounding box: xmin: 431649.4 ymin: 5337937 xmax: 438082.4 ymax: 5342956
#> Projected CRS: UTM Zone 17, Northern Hemisphere
#> First 10 features:
#> geometry
#> 1 POINT (438082.4 5342876)
#> 2 POINT (438062.5 5341462)
#> 3 POINT (437365.4 5342179)
#> 4 POINT (436668.3 5342896)
#> 5 POINT (438042.6 5340048)
#> 6 POINT (437345.5 5340765)
#> 7 POINT (436648.4 5341482)
#> 8 POINT (435951.3 5342199)
#> 9 POINT (435254.2 5342916)
#> 10 POINT (438022.7 5338634)
#--- perform grid sampling ---#
sample_systematic(
raster = sraster, # input sraster
cellsize = 500, # grid distance
square = FALSE, # hexagonal tessellation
location = "random", # randomly sample within tessellation
plot = TRUE
) # plot
#> Simple feature collection with 159 features and 0 fields
#> Geometry type: POINT
#> Dimension: XY
#> Bounding box: xmin: 431256.4 ymin: 5337710 xmax: 438512 ymax: 5343120
#> Projected CRS: UTM Zone 17, Northern Hemisphere
#> First 10 features:
#> geometry
#> 1 POINT (437888.8 5342929)
#> 2 POINT (437402.5 5342807)
#> 3 POINT (438396.3 5342616)
#> 4 POINT (436271.4 5343120)
#> 5 POINT (436983.9 5342810)
#> 6 POINT (437867.1 5342613)
#> 7 POINT (435016.1 5343115)
#> 8 POINT (435835 5342683)
#> 9 POINT (436461.5 5342540)
#> 10 POINT (437371.4 5342537)
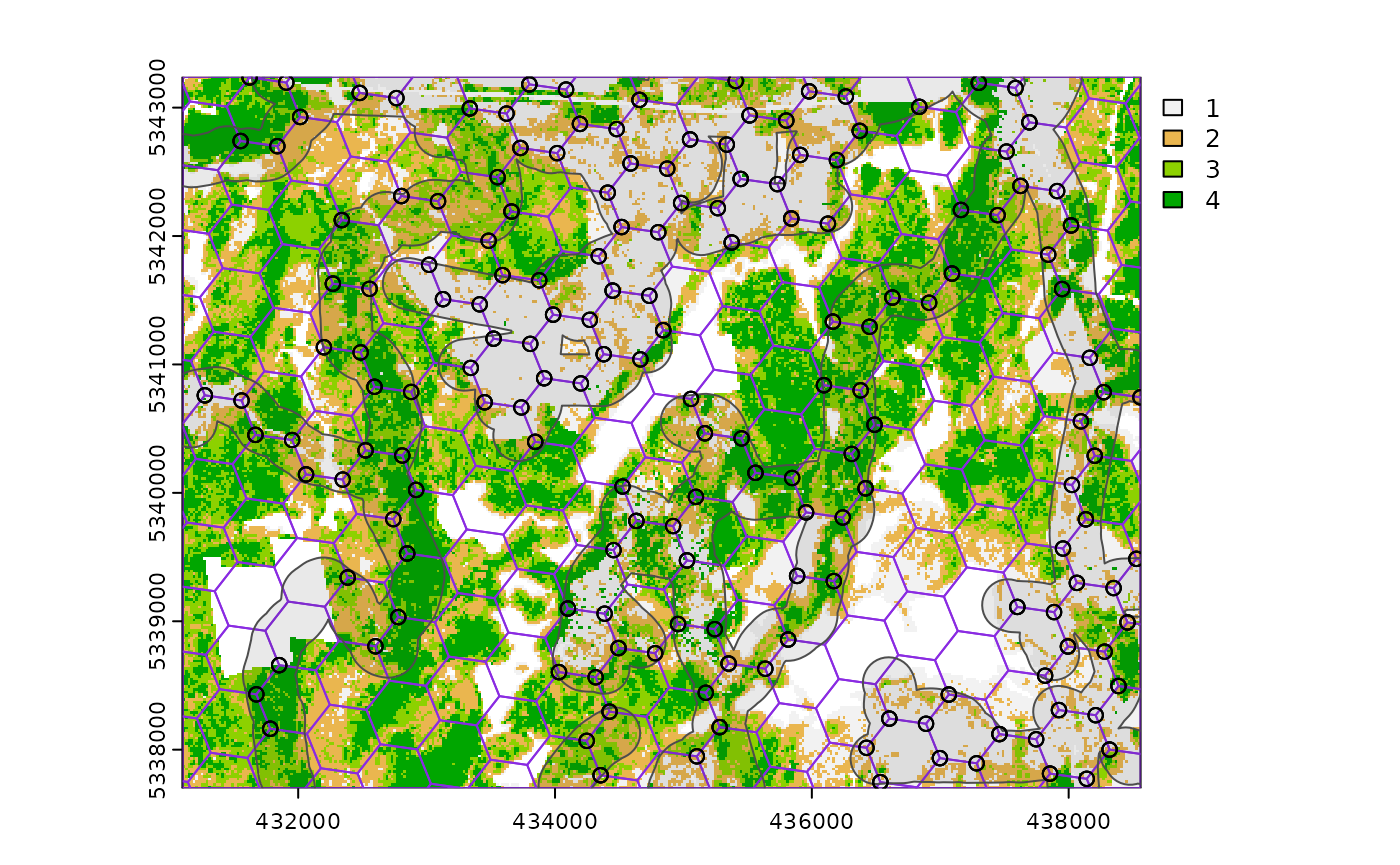
sample_systematic(
raster = sraster, # input sraster
cellsize = 500, # grid distance
access = access, # define access road network
buff_outer = 200, # outer buffer - no sample units further than this distance from road
square = FALSE, # hexagonal tessellation
location = "corners", # take corners instead of centers
plot = TRUE
)
#> Simple feature collection with 638 features and 0 fields
#> Geometry type: POINT
#> Dimension: XY
#> Bounding box: xmin: 431163 ymin: 5337738 xmax: 438494 ymax: 5343073
#> Projected CRS: UTM Zone 17, Northern Hemisphere
#> First 10 features:
#> geometry
#> 1 POINT (438494 5337746)
#> 2 POINT (438494 5337746)
#> 3 POINT (437994.1 5337738)
#> 4 POINT (438241.6 5337886)
#> 5 POINT (438494 5337746)
#> 6 POINT (438494 5337746)
#> 7 POINT (438241.6 5337886)
#> 8 POINT (438236.6 5338175)
#> 9 POINT (438484.1 5338324)
#> 10 POINT (437994.1 5337738)
sample_strat
The sample_strat() contains two methods to
perform sampling:
"Queinnec"- Hierarchical sampling using a focal window to isolate contiguous groups of stratum pixels, which was originally developed by Martin Queinnec."random"- Traditional stratified random sampling. Thismethodignores much of the functionality of the algorithm to allow users the capability to use standard stratified random sampling approaches without the use of a focal window to locate contiguous stratum cells.
method = "Queinnec"
Queinnec, M., White, J. C., & Coops, N. C. (2021). Comparing airborne and spaceborne photon-counting LiDAR canopy structural estimates across different boreal forest types. Remote Sensing of Environment, 262(August 2020), 112510.
This algorithm uses moving window (wrow and
wcol parameters) to filter the input sraster
to prioritize sample unit allocation to where stratum pixels are
spatially grouped, rather than dispersed individuals across the
landscape.
Sampling is performed using 2 rules:
Rule 1 - Sample within spatially grouped stratum pixels. Moving window defined by
wrowandwcol.Rule 2 - If no additional sample units exist to satisfy desired sample size(
nSamp), individual stratum pixels are sampled.
The rule applied to a select each sample unit is defined in the
rule attribute of output samples. We give a few examples
below:
#--- perform stratified sampling random sampling ---#
sample_strat(
sraster = sraster, # input sraster
nSamp = 200
) # desired sample size # plot
#> Simple feature collection with 200 features and 3 fields
#> Geometry type: POINT
#> Dimension: XY
#> Bounding box: xmin: 431150 ymin: 5337730 xmax: 438530 ymax: 5343210
#> Projected CRS: UTM Zone 17, Northern Hemisphere
#> First 10 features:
#> strata type rule geometry
#> x 1 new rule1 POINT (438090 5340810)
#> x1 1 new rule1 POINT (437850 5341210)
#> x2 1 new rule1 POINT (437810 5342370)
#> x3 1 new rule1 POINT (437450 5338850)
#> x4 1 new rule1 POINT (434650 5341630)
#> x5 1 new rule1 POINT (433950 5341010)
#> x6 1 new rule1 POINT (434170 5343190)
#> x7 1 new rule1 POINT (435570 5342170)
#> x8 1 new rule1 POINT (437970 5343210)
#> x9 1 new rule1 POINT (436530 5338050)In some cases, users might want to include an existing
sample within the algorithm. In order to adjust the total number of
sample units needed per stratum to reflect those already present in
existing, we can use the intermediate function
extract_strata().
This function uses the sraster and existing
sample units and extracts the stratum for each. These sample units can
be included within sample_strat(), which adjusts total
sample units required per class based on representation in
existing.
#--- extract strata values to existing samples ---#
e.sr <- extract_strata(
sraster = sraster, # input sraster
existing = existing
) # existing samples to add strata value toTIP!
sample_strat() requires the sraster input
to have an attribute named strata and will give an error if
it doesn’t.
sample_strat(
sraster = sraster, # input sraster
nSamp = 200, # desired sample size
access = access, # define access road network
existing = e.sr, # existing sample with strata values
mindist = 200, # minimum distance sample units must be apart from one another
buff_inner = 50, # inner buffer - no sample units within this distance from road
buff_outer = 200, # outer buffer - no sample units further than this distance from road
plot = TRUE
) # plot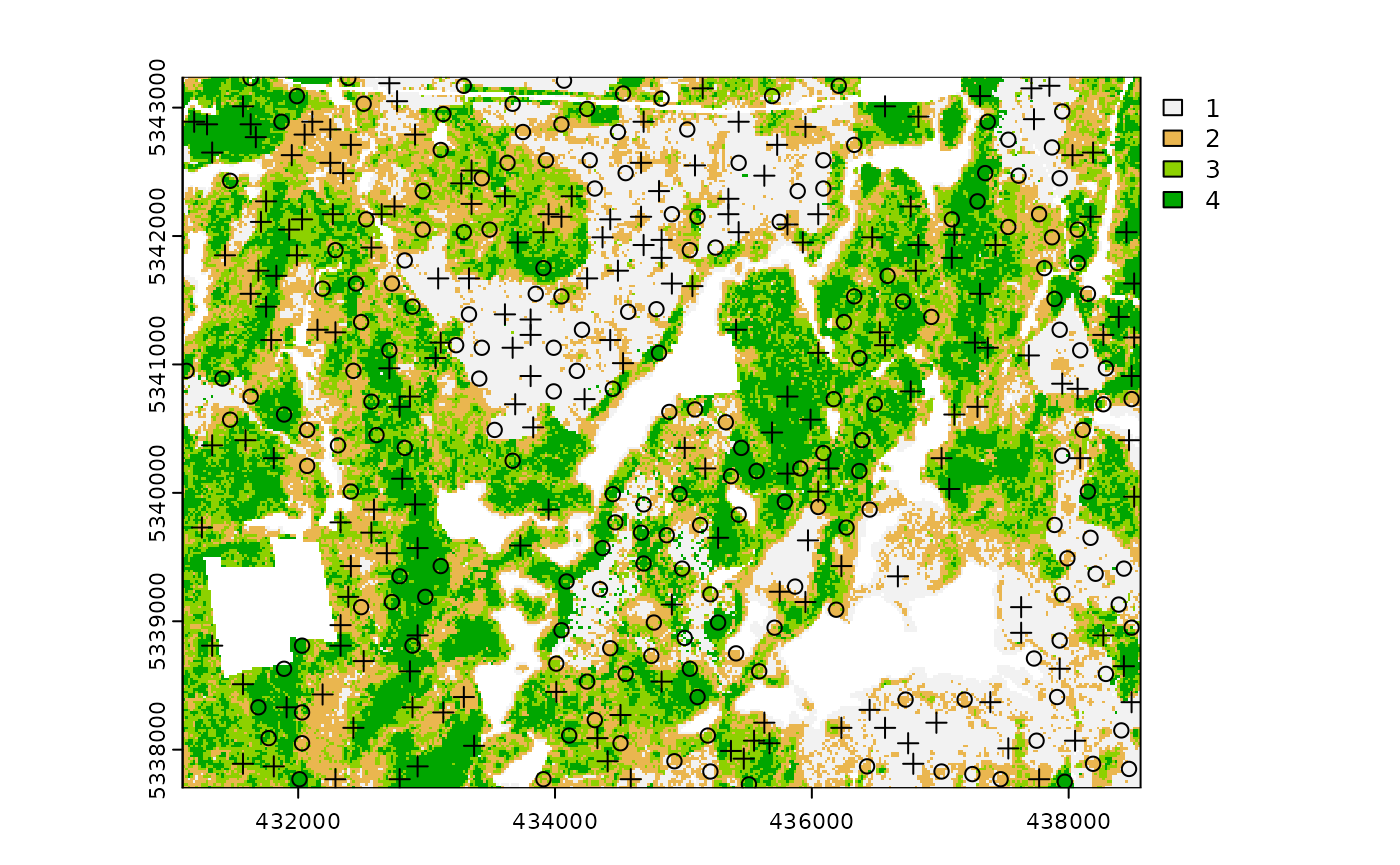
#> Simple feature collection with 400 features and 3 fields
#> Geometry type: POINT
#> Dimension: XY
#> Bounding box: xmin: 431130 ymin: 5337710 xmax: 438530 ymax: 5343230
#> Projected CRS: UTM Zone 17, Northern Hemisphere
#> First 10 features:
#> strata type rule geometry
#> 1 1 existing existing POINT (433810 5340930)
#> 2 1 existing existing POINT (438170 5340870)
#> 3 1 existing existing POINT (435710 5339510)
#> 4 1 existing existing POINT (433650 5342950)
#> 5 1 existing existing POINT (434810 5342130)
#> 6 1 existing existing POINT (437590 5342550)
#> 7 1 existing existing POINT (437150 5338290)
#> 8 1 existing existing POINT (435410 5342290)
#> 9 1 existing existing POINT (437950 5341170)
#> 10 1 existing existing POINT (437990 5341330)The code in the example above defined the mindist
parameter, which specifies the minimum euclidean distance that new
sample units must be apart from one another.
Notice that the sample units have type and
rule attributes which outline whether they are
existing or new, and whether
rule1 or rule2 were used to select them. If
type is existing (a user provided
existing sample), rule will be
existing as well as seen above.
sample_strat(
sraster = sraster, # input
nSamp = 200, # desired sample size
access = access, # define access road network
existing = e.sr, # existing samples with strata values
include = TRUE, # include existing sample in nSamp total
buff_outer = 200, # outer buffer - no samples further than this distance from road
plot = TRUE
) # plot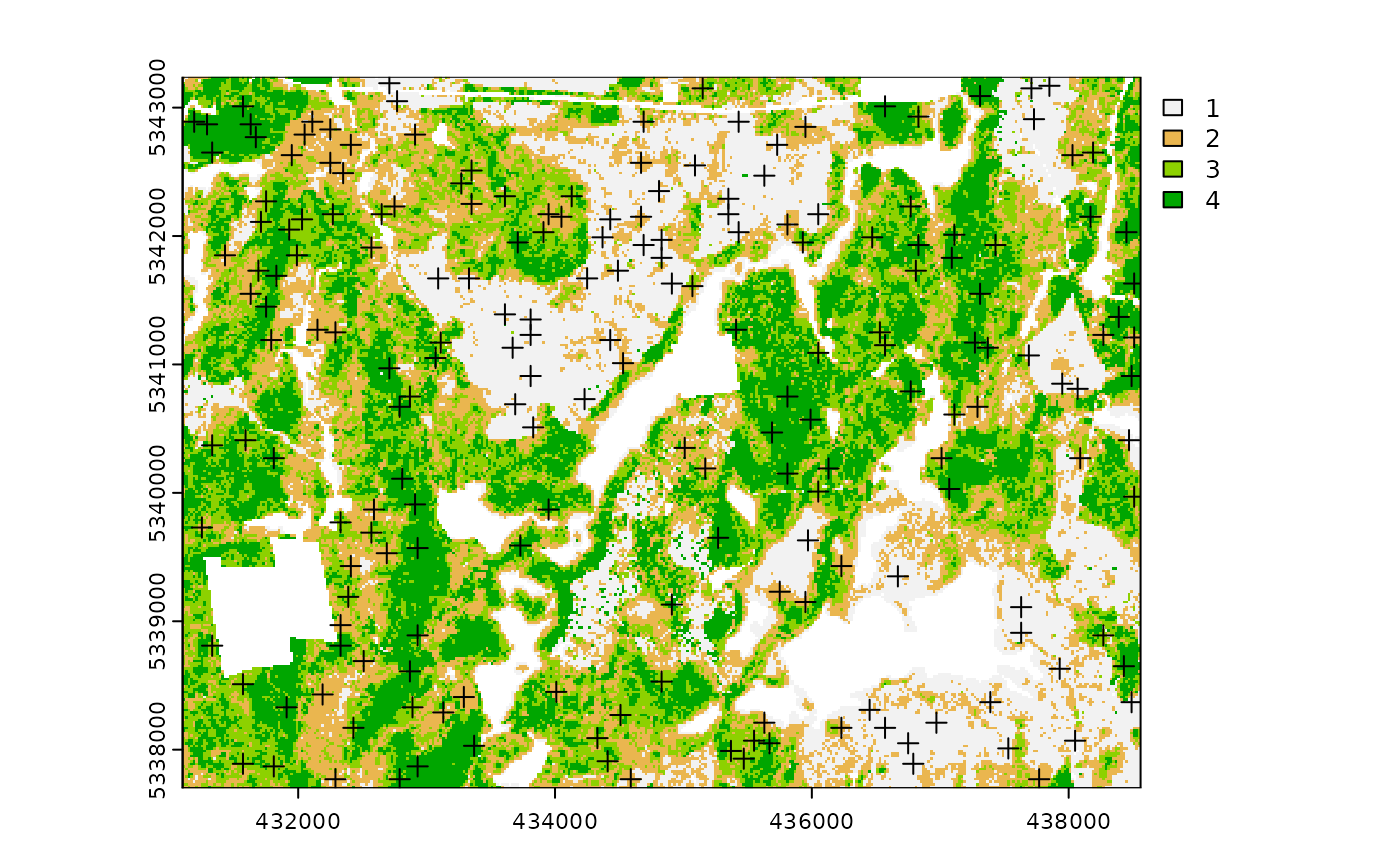
#> Simple feature collection with 200 features and 3 fields
#> Geometry type: POINT
#> Dimension: XY
#> Bounding box: xmin: 431130 ymin: 5337730 xmax: 438530 ymax: 5343190
#> Projected CRS: UTM Zone 17, Northern Hemisphere
#> First 10 features:
#> strata type rule geometry
#> 1 1 existing existing POINT (433810 5340930)
#> 2 1 existing existing POINT (438170 5340870)
#> 3 1 existing existing POINT (435710 5339510)
#> 4 1 existing existing POINT (433650 5342950)
#> 5 1 existing existing POINT (434810 5342130)
#> 6 1 existing existing POINT (437590 5342550)
#> 7 1 existing existing POINT (437150 5338290)
#> 8 1 existing existing POINT (435410 5342290)
#> 9 1 existing existing POINT (437950 5341170)
#> 10 1 existing existing POINT (437990 5341330)The include parameter determines whether
existing sample units should be included in the total
sample size defined by nSamp. By default, the
include parameter is set as FALSE.
method = "random
Stratified random sampling with equal probability for all cells
(using default algorithm values for mindist and no use of
access functionality). In essence this method perform the
sample_srs algorithm for each stratum separately to meet
the specified sample size.
#--- perform stratified sampling random sampling ---#
sample_strat(
sraster = sraster, # input sraster
method = "random", # stratified random sampling
nSamp = 200, # desired sample size
plot = TRUE
) # plot
#> Simple feature collection with 200 features and 2 fields
#> Geometry type: POINT
#> Dimension: XY
#> Bounding box: xmin: 431110 ymin: 5337790 xmax: 438550 ymax: 5343130
#> Projected CRS: UTM Zone 17, Northern Hemisphere
#> First 10 features:
#> strata type geometry
#> x 1 new POINT (437650 5340590)
#> x1 1 new POINT (437830 5338130)
#> x2 1 new POINT (436610 5339170)
#> x3 1 new POINT (436370 5339630)
#> x4 1 new POINT (433690 5341470)
#> x5 1 new POINT (437990 5339270)
#> x6 1 new POINT (437470 5339370)
#> x7 1 new POINT (434410 5341430)
#> x8 1 new POINT (438470 5339390)
#> x9 1 new POINT (434710 5341210)
sample_sys_strat
sample_sys_strat() function implements systematic
stratified sampling on an sraster. This function uses the
same functionality as sample_systematic() but takes an
sraster as input and performs sampling on each stratum
iteratively.
#--- perform grid sampling on each stratum separately ---#
sample_sys_strat(
sraster = sraster, # input sraster with 4 strata
cellsize = 1000, # grid size
plot = TRUE # plot output
)
#> Warning: [readStart] source already open for reading
#> Processing strata : 1
#> Warning: [extract] source already open for reading
#> Processing strata : 2
#> Warning: [extract] source already open for reading
#> Processing strata : 3
#> Warning: [extract] source already open for reading
#> Processing strata : 4
#> Warning: [extract] source already open for reading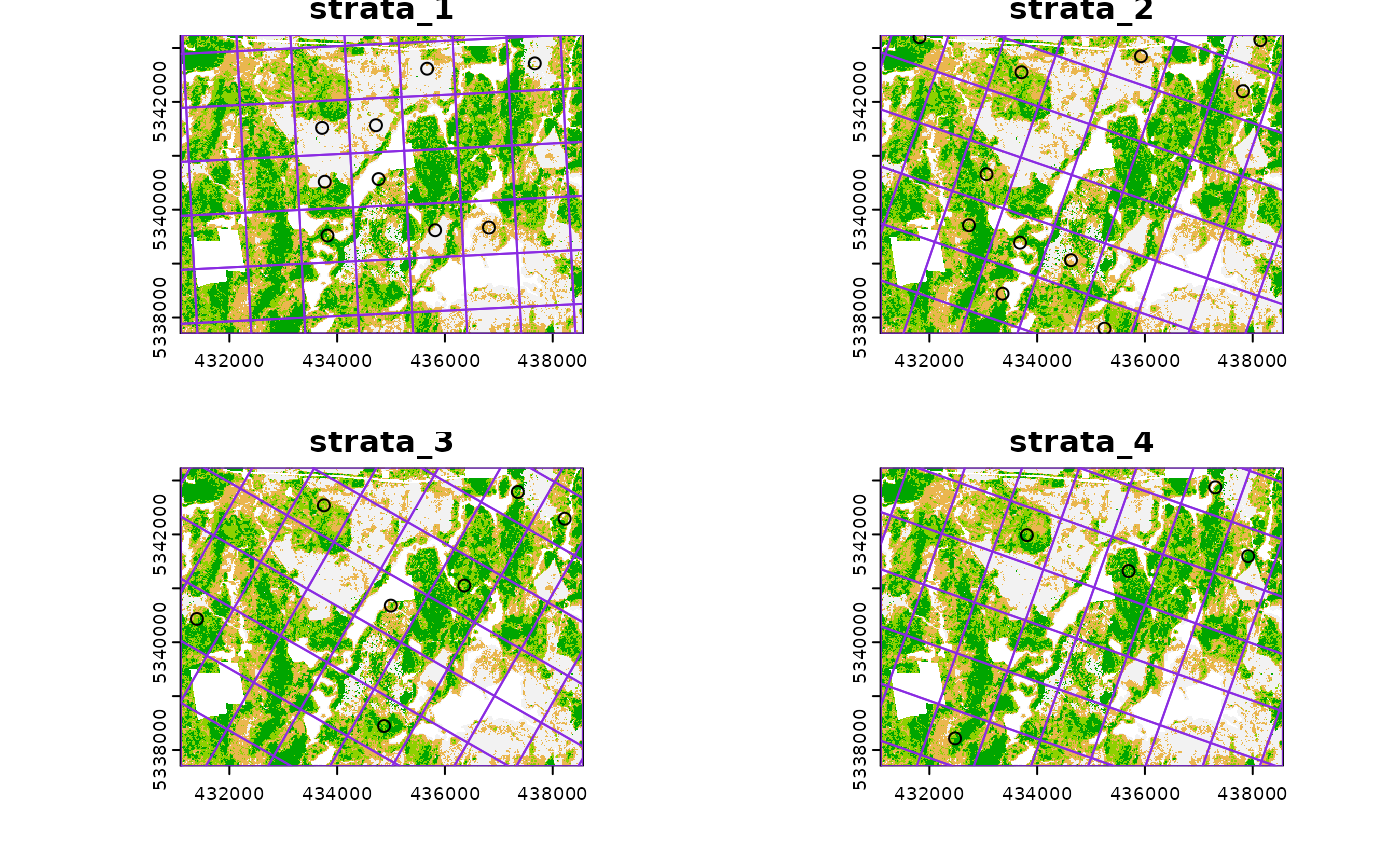
#> Simple feature collection with 36 features and 1 field
#> Geometry type: POINT
#> Dimension: XY
#> Bounding box: xmin: 431223.7 ymin: 5337766 xmax: 438341.2 ymax: 5343200
#> Projected CRS: UTM Zone 17, Northern Hemisphere
#> First 10 features:
#> strata geometry
#> 1 1 POINT (438341.2 5339421)
#> 2 1 POINT (437927.3 5340332)
#> 3 1 POINT (435775.3 5342649)
#> 4 1 POINT (435278.9 5341325)
#> 5 1 POINT (434865 5342235)
#> 6 1 POINT (435196.4 5339090)
#> 7 1 POINT (434368.6 5340911)
#> 8 1 POINT (434700 5337766)
#> 9 1 POINT (433044.3 5341407)
#> 10 1 POINT (431223.7 5340579)Just like with sample_systematic() we can specify where
we want our samples to fall within our tessellations. We specify
location = "corners" below. Note that the tesselations are
all saved to a list file when details = TRUE should the
user want to save them.
sample_sys_strat(
sraster = sraster, # input sraster with 4 strata
cellsize = 500, # grid size
square = FALSE, # hexagon tessellation
location = "corners", # samples on tessellation corners
plot = TRUE # plot output
)
#> Processing strata : 1
#> Warning: [extract] source already open for reading
#> Processing strata : 2
#> Warning: [extract] source already open for reading
#> Processing strata : 3
#> Warning: [extract] source already open for reading
#> Processing strata : 4
#> Warning: [extract] source already open for reading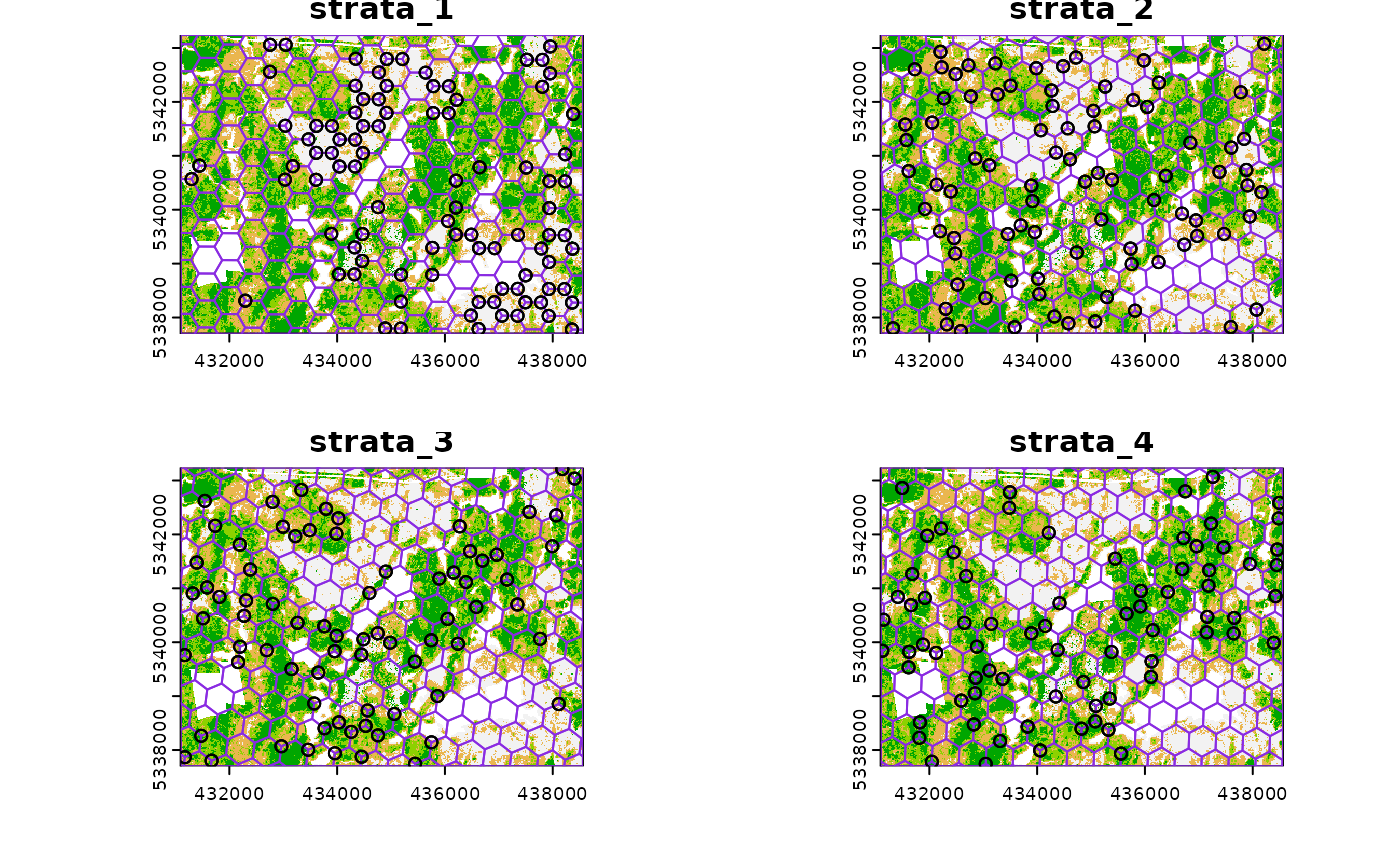
#> Simple feature collection with 1211 features and 1 field
#> Geometry type: POINT
#> Dimension: XY
#> Bounding box: xmin: 431115.2 ymin: 5337729 xmax: 438551 ymax: 5343222
#> Projected CRS: UTM Zone 17, Northern Hemisphere
#> First 10 features:
#> strata geometry
#> 1 1 POINT (432757.6 5343086)
#> 2 1 POINT (432757.6 5343086)
#> 3 1 POINT (433254.1 5343145)
#> 4 1 POINT (432757.6 5343086)
#> 5 1 POINT (432757.6 5343086)
#> 6 1 POINT (432825.3 5342513)
#> 7 1 POINT (433254.1 5343145)
#> 8 1 POINT (433750.7 5343203)
#> 9 1 POINT (433519.3 5343031)
#> 10 1 POINT (433254.1 5343145)This sampling approach could be especially useful incombination with
strat_poly() to ensure consistency of sampling accross
specific management units.
#--- read polygon coverage ---#
poly <- system.file("extdata", "inventory_polygons.shp", package = "sgsR")
fri <- sf::st_read(poly)
#> Reading layer `inventory_polygons' from data source
#> `/home/runner/work/_temp/Library/sgsR/extdata/inventory_polygons.shp'
#> using driver `ESRI Shapefile'
#> Simple feature collection with 632 features and 3 fields
#> Geometry type: MULTIPOLYGON
#> Dimension: XY
#> Bounding box: xmin: 431100 ymin: 5337700 xmax: 438560 ymax: 5343240
#> Projected CRS: UTM_Zone_17_Northern_Hemisphere
#--- stratify polygon coverage ---#
#--- specify polygon attribute to stratify ---#
attribute <- "NUTRIENTS"
#--- specify features within attribute & how they should be grouped ---#
#--- as a single vector ---#
features <- c("poor", "rich", "medium")
#--- get polygon stratification ---#
srasterpoly <- strat_poly(
poly = fri,
attribute = attribute,
features = features,
raster = sraster
)
#--- systematatic stratified sampling for each stratum ---#
sample_sys_strat(
sraster = srasterpoly, # input sraster from strat_poly() with 3 strata
cellsize = 500, # grid size
square = FALSE, # hexagon tessellation
location = "random", # randomize plot location
plot = TRUE # plot output
)
#> Processing strata : 1
#> Warning: [extract] source already open for reading
#> Processing strata : 2
#> Warning: [extract] source already open for reading
#> Processing strata : 3
#> Warning: [extract] source already open for reading
#> Simple feature collection with 172 features and 1 field
#> Geometry type: POINT
#> Dimension: XY
#> Bounding box: xmin: 431103.6 ymin: 5337700 xmax: 438553 ymax: 5343237
#> Projected CRS: UTM Zone 17, Northern Hemisphere
#> First 10 features:
#> strata geometry
#> 1 1 POINT (437892.6 5338057)
#> 2 1 POINT (438053.3 5338438)
#> 3 1 POINT (437943.2 5338196)
#> 4 1 POINT (437737 5338686)
#> 5 1 POINT (438066.4 5339322)
#> 6 1 POINT (436866.4 5337964)
#> 7 1 POINT (438188 5339645)
#> 8 1 POINT (437561.1 5339340)
#> 9 1 POINT (437875.9 5339644)
#> 10 1 POINT (435742.7 5337922)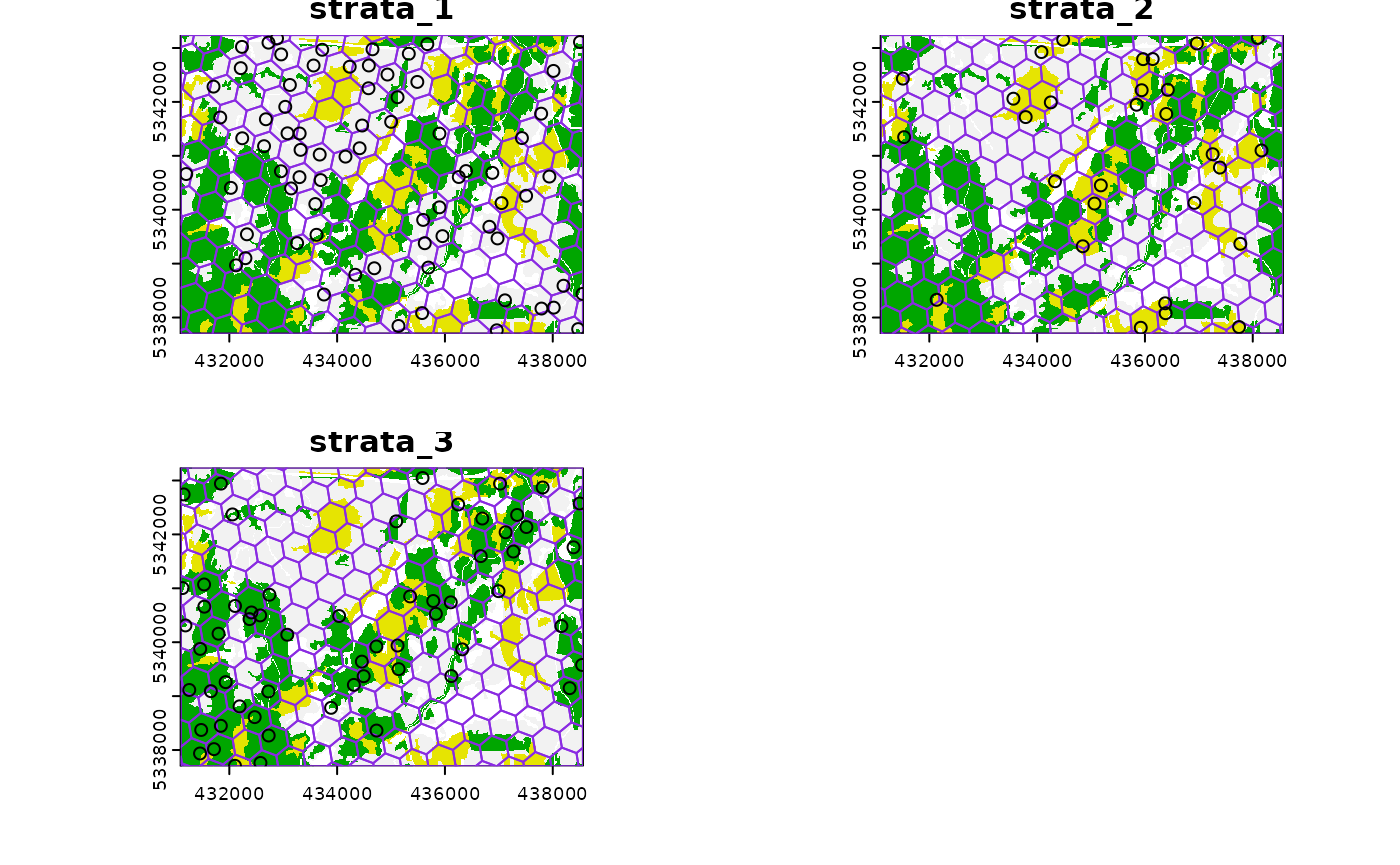
sample_nc
sample_nc() function implements the Nearest Centroid
sampling algorithm described in Melville &
Stone (2016). The algorithm uses kmeans clustering where the number
of clusters (centroids) is equal to the desired sample size
(nSamp).
Cluster centers are located, which then prompts the nearest neighbour
mraster pixel for each cluster to be selected (assuming
default k parameter). These nearest neighbours are the
output sample units.
#--- perform simple random sampling ---#
sample_nc(
mraster = mraster, # input
nSamp = 25, # desired sample size
plot = TRUE
)
#> K-means being performed on 3 layers with 25 centers.
#> Simple feature collection with 25 features and 4 fields
#> Geometry type: POINT
#> Dimension: XY
#> Bounding box: xmin: 431110 ymin: 5337730 xmax: 438450 ymax: 5343130
#> Projected CRS: UTM Zone 17, Northern Hemisphere
#> First 10 features:
#> zq90 pzabove2 zsd kcenter geometry
#> 7646 5.75 56.2 1.35 1 POINT (434810 5342830)
#> 11400 9.09 62.5 2.35 2 POINT (435290 5342630)
#> 63615 19.50 20.9 6.20 3 POINT (435190 5339830)
#> 26124 16.10 94.5 2.84 4 POINT (431370 5341830)
#> 34254 19.90 86.6 5.69 5 POINT (437310 5341410)
#> 67376 8.62 38.7 2.32 6 POINT (435810 5339630)
#> 44122 19.50 65.1 5.84 7 POINT (433250 5340870)
#> 39309 4.50 28.9 1.03 8 POINT (433970 5341130)
#> 47146 3.07 6.7 0.60 9 POINT (434050 5340710)
#> 87292 16.20 88.7 3.92 10 POINT (431290 5338550)Altering the k parameter leads to a multiplicative
increase in output sample units where total output samples =
.
#--- perform simple random sampling ---#
samples <- sample_nc(
mraster = mraster, # input
k = 2, # number of nearest neighbours to take for each kmeans center
nSamp = 25, # desired sample size
plot = TRUE
)
#> K-means being performed on 3 layers with 25 centers.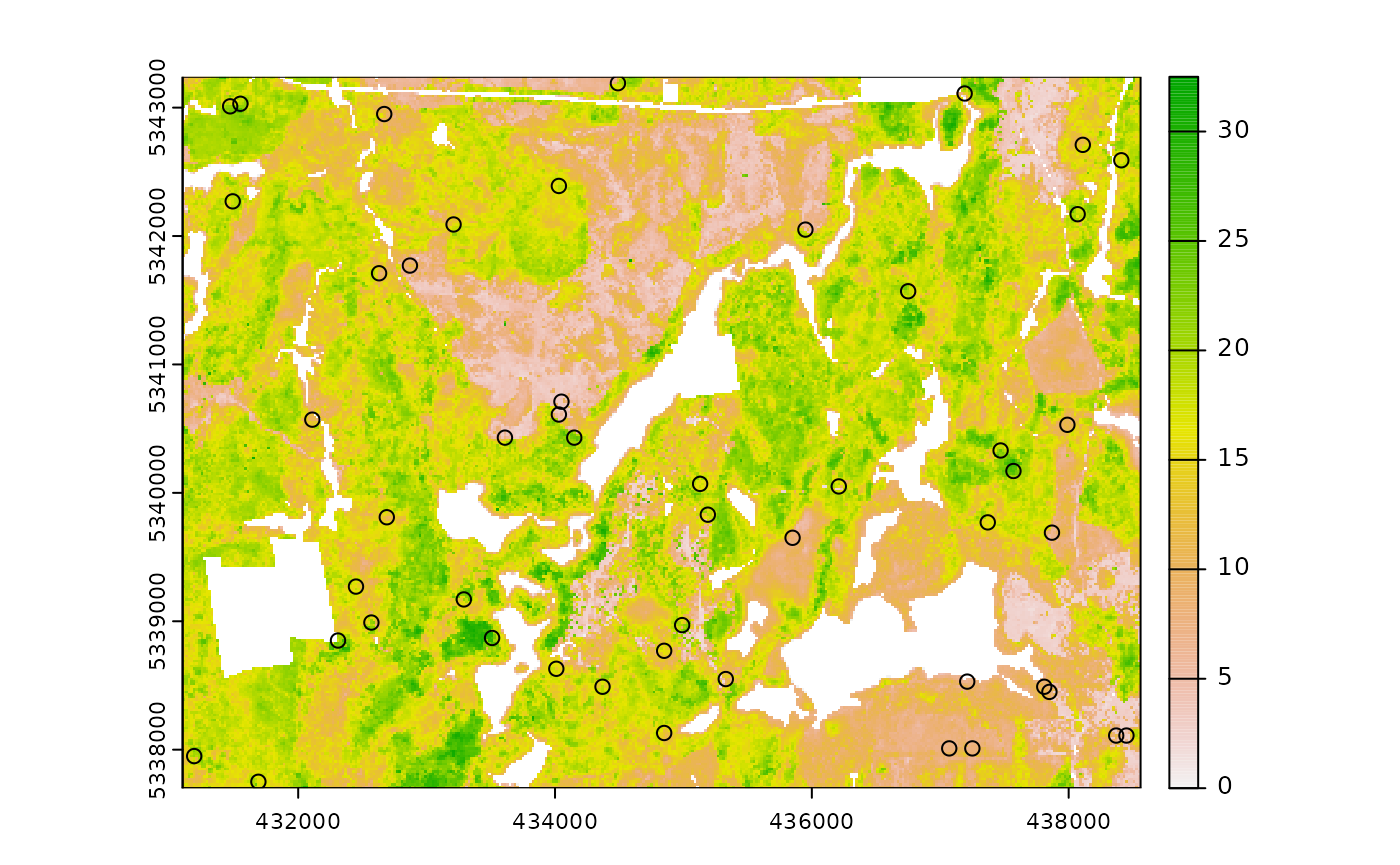
#--- total samples = nSamp * k (25 * 2) = 50 ---#
nrow(samples)
#> [1] 50Visualizing what the kmeans centers and sample units looks like is
possible when using details = TRUE. The $kplot
output provides a quick visualization of where the centers are based on
a scatter plot of the first 2 layers in mraster. Notice
that the centers are well distributed in covariate space and chosen
sample units are the closest pixels to each center (nearest
neighbours).
#--- perform simple random sampling with details ---#
details <- sample_nc(
mraster = mraster, # input
nSamp = 25, # desired sample number
details = TRUE
)
#> K-means being performed on 3 layers with 25 centers.
#--- plot ggplot output ---#
details$kplot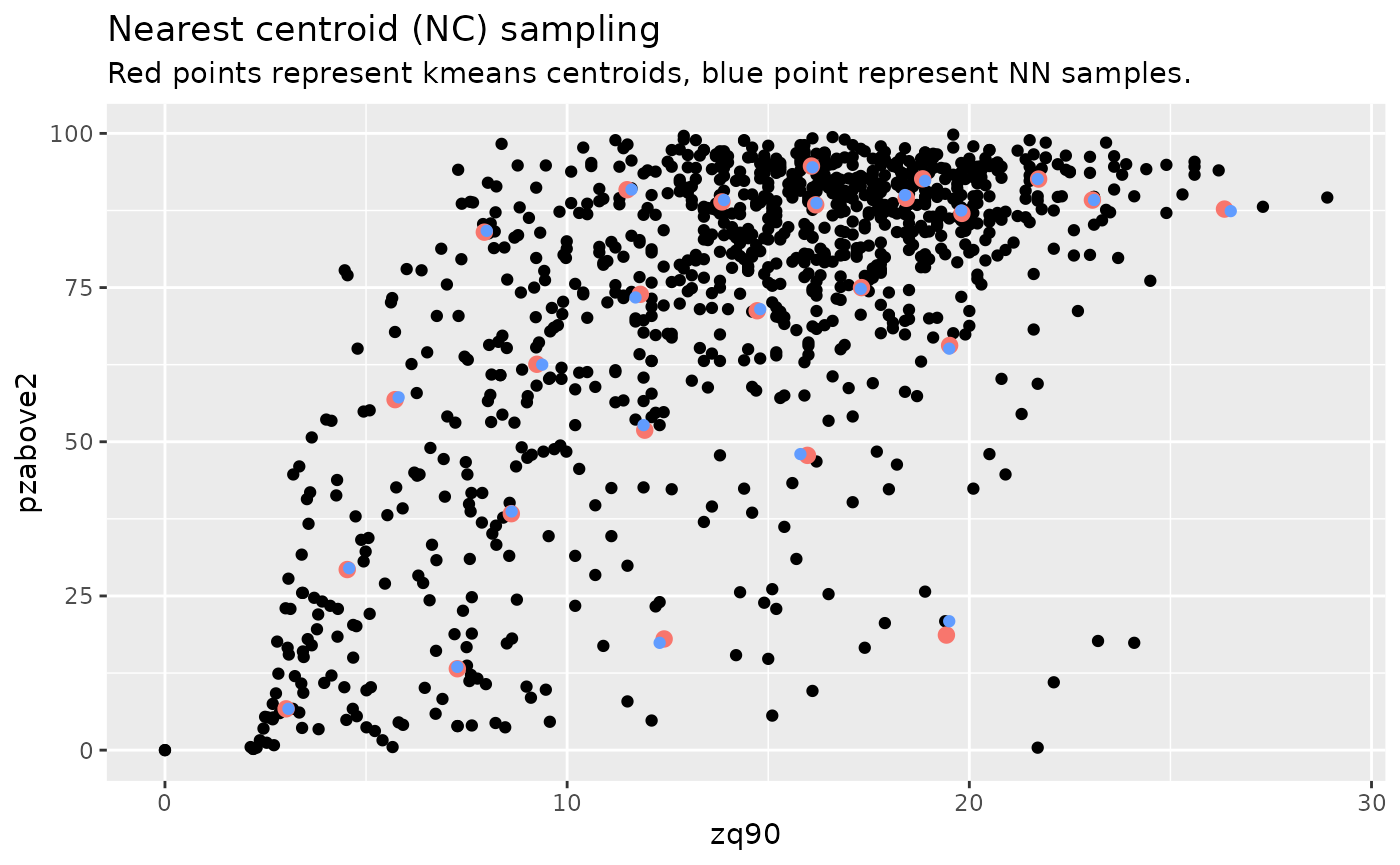
sample_clhs
sample_clhs() function implements conditioned Latin
hypercube (clhs) sampling methodology from the clhs
package.
TIP!
A number of other functions in the sgsR package help to
provide guidance on clhs sampling including calculate_pop()
and calculate_lhsOpt(). Check out these functions to better
understand how sample numbers could be optimized.
The syntax for this function is similar to others shown above,
although parameters like iter, which define the number of
iterations within the Metropolis-Hastings process are important to
consider. In these examples we use a low iter value for
efficiency. Default values for iter within the
clhs package are 10,000.
sample_clhs(
mraster = mraster, # input
nSamp = 200, # desired sample size
plot = TRUE, # plot
iter = 100
) # number of iterations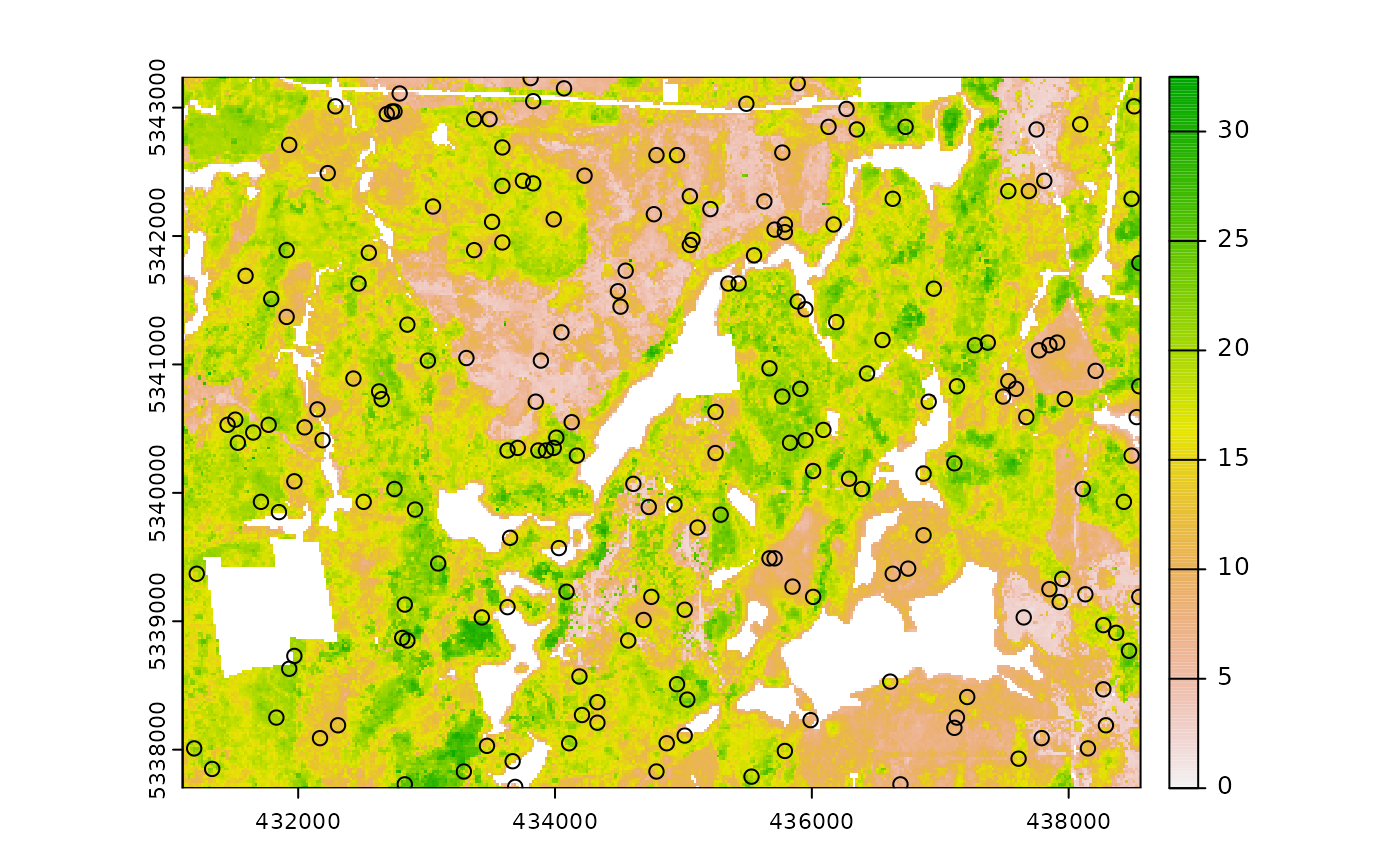
The cost parameter defines the mraster
covariate, which is used to constrain the clhs sampling. An example
could be the distance a pixel is from road access
(e.g. from calculate_distance() see example below), terrain
slope, the output from calculate_coobs(), or many
others.
#--- cost constrained examples ---#
#--- calculate distance to access layer for each pixel in mr ---#
mr.c <- calculate_distance(
raster = mraster, # input
access = access, # define access road network
plot = TRUE
) # plot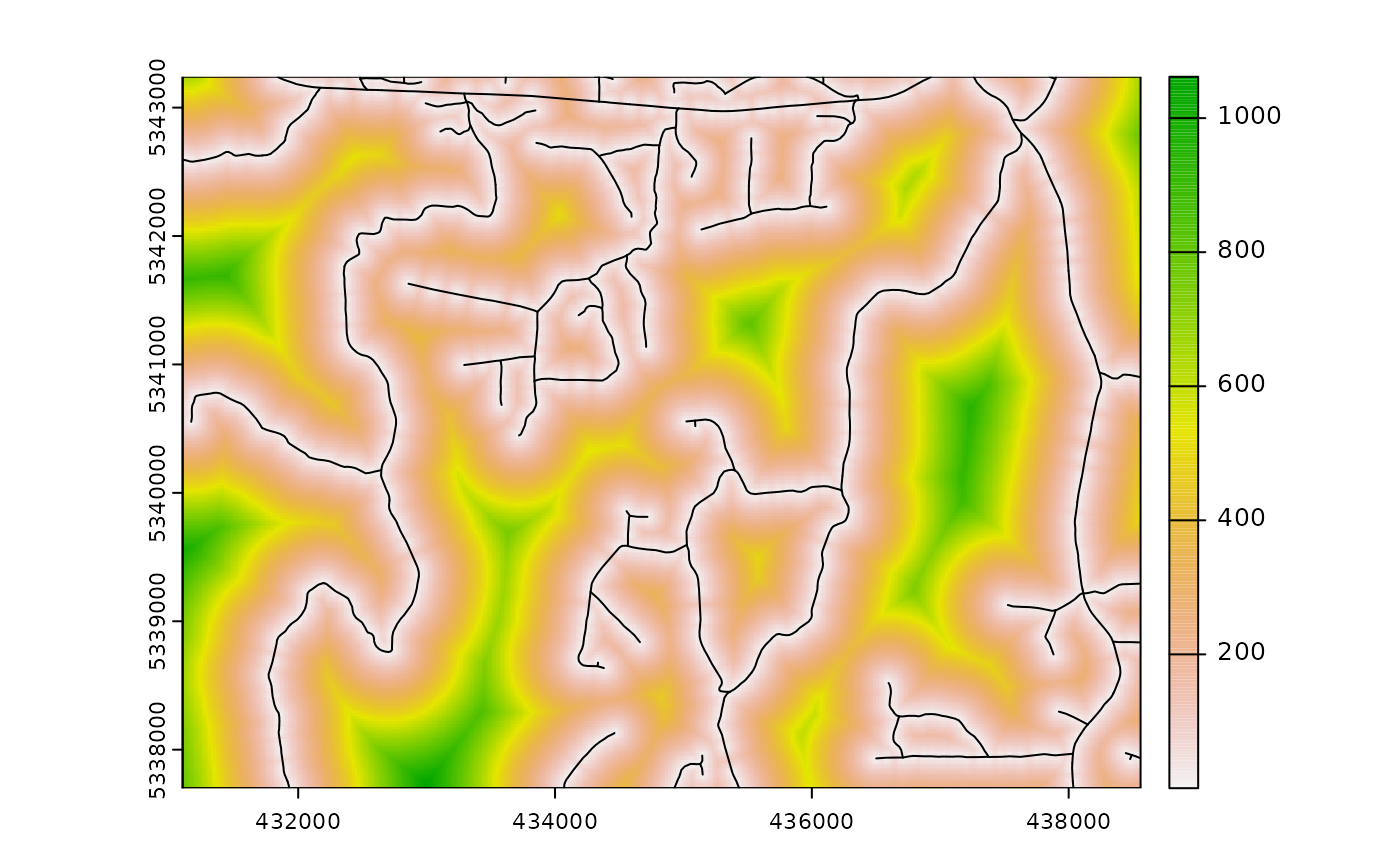
sample_clhs(
mraster = mr.c, # input
nSamp = 250, # desired sample size
iter = 100, # number of iterations
cost = "dist2access", # cost parameter - name defined in calculate_distance()
plot = TRUE
) # plot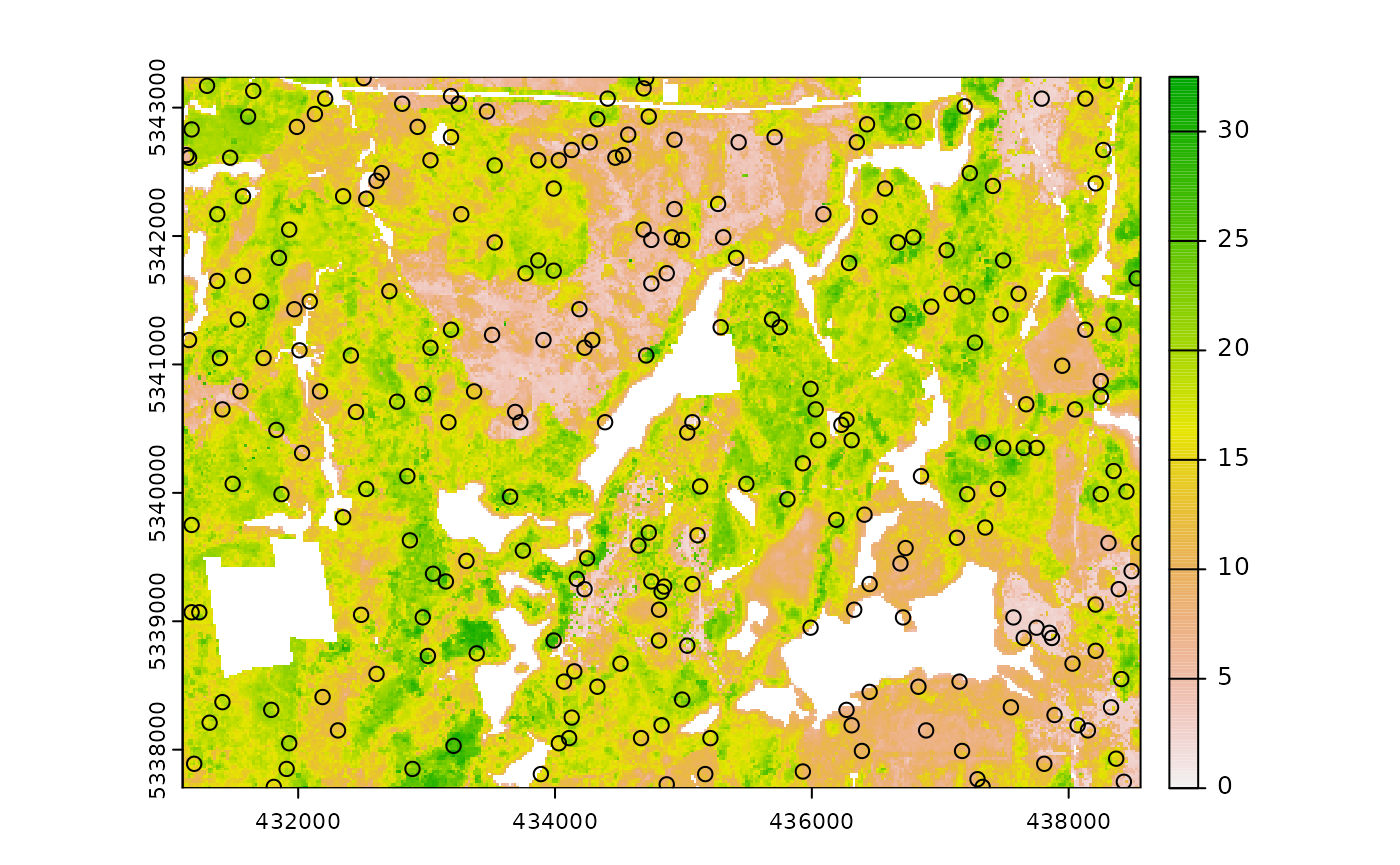
sample_balanced
The sample_balanced() algorithm performs a balanced
sampling methodology from the stratifyR / SamplingBigData
packages.
sample_balanced(
mraster = mraster, # input
nSamp = 200, # desired sample size
plot = TRUE
) # plot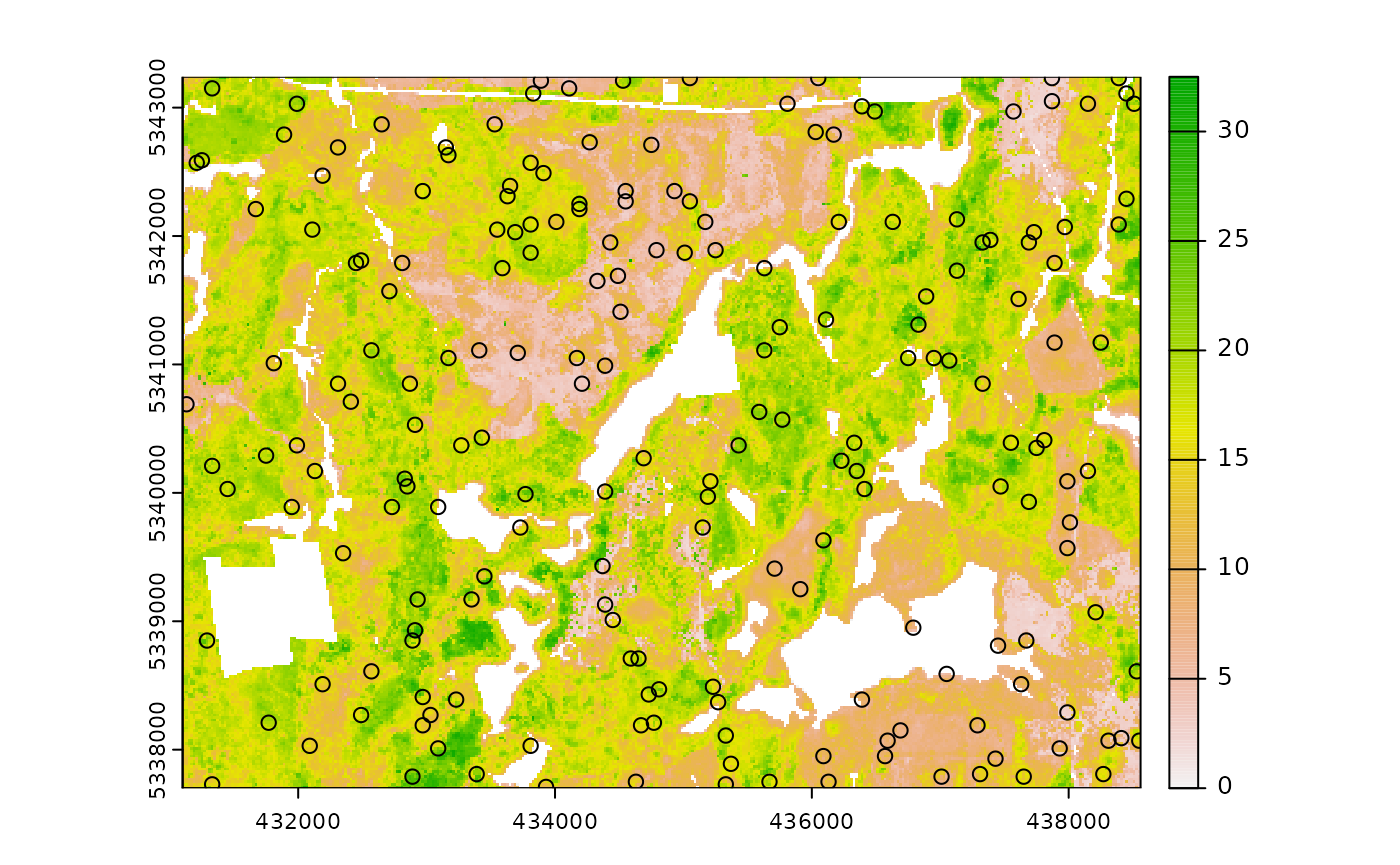
#> Simple feature collection with 200 features and 0 fields
#> Geometry type: POINT
#> Dimension: XY
#> Bounding box: xmin: 431110 ymin: 5337770 xmax: 438550 ymax: 5343170
#> Projected CRS: +proj=utm +zone=17 +ellps=GRS80 +towgs84=0,0,0,0,0,0,0 +units=m +no_defs
#> First 10 features:
#> geometry
#> 1 POINT (433070 5343170)
#> 2 POINT (437490 5343170)
#> 3 POINT (433830 5343130)
#> 4 POINT (434070 5343030)
#> 5 POINT (438270 5343030)
#> 6 POINT (432070 5343010)
#> 7 POINT (435470 5342930)
#> 8 POINT (432410 5342850)
#> 9 POINT (436970 5342850)
#> 10 POINT (431130 5342830)
sample_balanced(
mraster = mraster, # input
nSamp = 100, # desired sample size
algorithm = "lcube", # algorithm type
access = access, # define access road network
buff_inner = 50, # inner buffer - no sample units within this distance from road
buff_outer = 200
) # outer buffer - no sample units further than this distance from road
#> Simple feature collection with 100 features and 0 fields
#> Geometry type: POINT
#> Dimension: XY
#> Bounding box: xmin: 431130 ymin: 5337710 xmax: 438390 ymax: 5343130
#> Projected CRS: +proj=utm +zone=17 +ellps=GRS80 +towgs84=0,0,0,0,0,0,0 +units=m +no_defs
#> First 10 features:
#> geometry
#> 1 POINT (435610 5343130)
#> 2 POINT (434730 5343110)
#> 3 POINT (431770 5343090)
#> 4 POINT (434510 5343090)
#> 5 POINT (437270 5343070)
#> 6 POINT (432750 5342990)
#> 7 POINT (433910 5342990)
#> 8 POINT (433210 5342970)
#> 9 POINT (434490 5342910)
#> 10 POINT (435770 5342910)
sample_ahels
The sample_ahels() function performs the adapted
Hypercube Evaluation of a Legacy Sample (ahels) algorithm
usingexisting sample data and an mraster. New
sample units are allocated based on quantile ratios between the
existing sample and mraster covariate
dataset.
This algorithm was adapted from that presented in the paper below, which we highly recommend.
Malone BP, Minansy B, Brungard C. 2019. Some methods to improve the utility of conditioned Latin hypercube sampling. PeerJ 7:e6451 DOI 10.7717/peerj.6451
This algorithm:
Determines the quantile distributions of
existingsample units andmrastercovariates.Determines quantiles where there is a disparity between sample units and covariates.
Prioritizes sampling within those quantile to improve representation.
To use this function, user must first specify the number of quantiles
(nQuant) followed by either the nSamp (total
number of desired sample units to be added) or the
threshold (sampling ratio vs. covariate coverage ratio for
quantiles - default is 0.9) parameters.
#--- remove `type` variable from existing - causes plotting issues ---#
existing <- existing %>% select(-type)
sample_ahels(
mraster = mraster,
existing = existing, # existing sample
plot = TRUE
) # plot#> Simple feature collection with 300 features and 7 fields
#> Geometry type: POINT
#> Dimension: XY
#> Bounding box: xmin: 431130 ymin: 5337730 xmax: 438530 ymax: 5343210
#> Projected CRS: UTM Zone 17, Northern Hemisphere
#> First 10 features:
#> type.x zq90 pzabove2 zsd strata type.y rule
#> 1 existing 8.59 6.1 2.06 1 new rule1
#> 2 existing 7.38 93.7 1.38 1 new rule1
#> 3 existing 7.64 30.7 1.97 1 new rule1
#> 4 existing 4.45 51.3 1.20 1 new rule1
#> 5 existing 5.46 40.4 1.24 1 new rule1
#> 6 existing 2.69 5.3 0.71 1 new rule1
#> 7 existing 9.69 81.8 2.30 1 new rule1
#> 8 existing 4.85 33.8 1.11 1 new rule1
#> 9 existing 8.10 95.5 1.38 1 new rule1
#> 10 existing 6.97 62.4 1.63 1 new rule1
#> geometry
#> 1 POINT (433810 5340930)
#> 2 POINT (438170 5340870)
#> 3 POINT (435710 5339510)
#> 4 POINT (433650 5342950)
#> 5 POINT (434810 5342130)
#> 6 POINT (437590 5342550)
#> 7 POINT (437150 5338290)
#> 8 POINT (435410 5342290)
#> 9 POINT (437950 5341170)
#> 10 POINT (437990 5341330)TIP!
Notice that no threshold, nSamp, or
nQuant were defined. That is because the default setting
for threshold = 0.9 and nQuant = 10.
The first matrix output shows the quantile ratios between the sample and the covariates. A value of 1.0 indicates that the sample is representative of quantile coverage. Values > 1.0 indicate over representation of sample units, while < 1.0 indicate under representation.
sample_ahels(
mraster = mraster,
existing = existing, # existing sample
nQuant = 20, # define 20 quantiles
nSamp = 300
) # desired sample size#> Simple feature collection with 500 features and 7 fields
#> Geometry type: POINT
#> Dimension: XY
#> Bounding box: xmin: 431130 ymin: 5337710 xmax: 438550 ymax: 5343210
#> Projected CRS: UTM Zone 17, Northern Hemisphere
#> First 10 features:
#> type.x zq90 pzabove2 zsd strata type.y rule
#> 1 existing 8.59 6.1 2.06 1 new rule1
#> 2 existing 7.38 93.7 1.38 1 new rule1
#> 3 existing 7.64 30.7 1.97 1 new rule1
#> 4 existing 4.45 51.3 1.20 1 new rule1
#> 5 existing 5.46 40.4 1.24 1 new rule1
#> 6 existing 2.69 5.3 0.71 1 new rule1
#> 7 existing 9.69 81.8 2.30 1 new rule1
#> 8 existing 4.85 33.8 1.11 1 new rule1
#> 9 existing 8.10 95.5 1.38 1 new rule1
#> 10 existing 6.97 62.4 1.63 1 new rule1
#> geometry
#> 1 POINT (433810 5340930)
#> 2 POINT (438170 5340870)
#> 3 POINT (435710 5339510)
#> 4 POINT (433650 5342950)
#> 5 POINT (434810 5342130)
#> 6 POINT (437590 5342550)
#> 7 POINT (437150 5338290)
#> 8 POINT (435410 5342290)
#> 9 POINT (437950 5341170)
#> 10 POINT (437990 5341330)Notice that the total number of samples is 500. This value is the sum
of existing units (200) and number of sample units defined by
nSamp = 300.
sample_existing
Acknowledging that existing sample networks are common
is important. There is significant investment into these samples, and in
order to keep inventories up-to-date, we often need to collect new data
for sample units. The sample_existing algorithm provides
the user with methods for sub-sampling an existing sample
network should the financial / logistical resources not be available to
collect data at all sample units. The functions allows users to choose
between algorithm types using (type = "clhs" - default,
type = "balanced", type = "srs",
type = "strat"). Differences in type result in calling
internal sample_existing_*() functions
(sample_existing_clhs() (default),
sample_existing_balanced(),
sample_existing_srs(),
sample_existing_strat()). These functions are not exported
to be used stand-alone, however they employ the same functionality as
their sample_clhs() etc counterparts.
While using sample_existing(), should the user wish to
specify algorithm specific parameters
(e.g. algorithm = "lcube" in sample_balanced()
or allocation = "equal" in sample_strat()),
they can specify within sample_existing() as if calling the
function directly.
I give applied examples for all methods below that are based on the following scenario:
We have a systematic sample where sample units are 200m apart.
We know we only have resources to sample 300 of them.
We have some ALS data available (
mraster), which we can use to improve knowledge of the metric populations.
See our existing sample for the scenario below.
#--- generate existing samples and extract metrics ---#
existing <- sample_systematic(raster = mraster, cellsize = 200, plot = TRUE)
#--- sub sample using ---#
e <- existing %>%
extract_metrics(mraster = mraster, existing = .)
sample_existing(type = "clhs")
The algorithm is unique in that it has two fundamental approaches:
- Sample exclusively using
existingand the attributes it contains.
#--- sub sample using ---#
sample_existing(existing = e, nSamp = 300, type = "clhs")
#> Simple feature collection with 300 features and 3 fields
#> Geometry type: POINT
#> Dimension: XY
#> Bounding box: xmin: 431104.5 ymin: 5337701 xmax: 438554.7 ymax: 5343223
#> Projected CRS: UTM Zone 17, Northern Hemisphere
#> First 10 features:
#> zq90 pzabove2 zsd geometry
#> 66 17.70 82.1 4.04 POINT (435439.9 5337975)
#> 657 21.60 65.0 6.44 POINT (438397 5341288)
#> 888 14.00 79.4 3.60 POINT (437944.4 5342742)
#> 2 18.10 94.2 3.97 POINT (431399.3 5337791)
#> 389 16.60 82.7 4.68 POINT (432682.5 5340473)
#> 786 4.08 37.2 0.83 POINT (435495.4 5342393)
#> 351 12.00 89.1 3.04 POINT (432065.1 5340335)
#> 182 13.40 23.8 3.46 POINT (434328.7 5338895)
#> 523 15.70 84.7 4.11 POINT (431571.4 5341392)
#> 201 19.00 90.0 5.04 POINT (433155.7 5339217)- Sub-sampling using
rasterdistributions
Our systematic sample of ~900 plots is fairly comprehensive, however
we can generate a true population distribution through the inclusion of
the ALS metrics in the sampling process. The metrics will be included in
internal latin hypercube sampling to help guide sub-sampling of
existing.
#--- sub sample using ---#
sample_existing(
existing = existing, # our existing sample
nSamp = 300, # desired sample size
raster = mraster, # include mraster metrics to guide sampling of existing
plot = TRUE
) # plot
#> Simple feature collection with 300 features and 3 fields
#> Geometry type: POINT
#> Dimension: XY
#> Bounding box: xmin: 431104.5 ymin: 5337701 xmax: 438547.5 ymax: 5343230
#> Projected CRS: +proj=utm +zone=17 +ellps=GRS80 +towgs84=0,0,0,0,0,0,0 +units=m +no_defs
#> First 10 features:
#> zq90 pzabove2 zsd geometry
#> 91722 7.13 51.7 2.10 POINT (432367.1 5341310)
#> 92096 16.80 98.4 2.79 POINT (437368.3 5343003)
#> 91813 14.60 89.2 3.75 POINT (437381.7 5341192)
#> 91267 6.11 78.1 1.43 POINT (436633.5 5337852)
#> 91270 7.43 81.0 1.71 POINT (437230.3 5337790)
#> 92090 15.80 88.8 4.37 POINT (435776.8 5343168)
#> 91466 8.24 36.3 2.08 POINT (435584.1 5339368)
#> 91797 4.57 68.3 1.01 POINT (433800.9 5341563)
#> 91228 20.50 96.8 3.63 POINT (433628.8 5337962)
#> 91377 13.40 23.8 3.46 POINT (434328.7 5338895)The sample distribution again mimics the population distribution quite well! Now lets try using a cost variable to constrain the sub-sample.
#--- create distance from roads metric ---#
dist <- calculate_distance(raster = mraster, access = access)
#--- sub sample using ---#
sample_existing(
existing = existing, # our existing sample
nSamp = 300, # desired sample size
raster = dist, # include mraster metrics to guide sampling of existing
cost = 4, # either provide the index (band number) or the name of the cost layer
plot = TRUE
) # plot
#> Simple feature collection with 300 features and 4 fields
#> Geometry type: POINT
#> Dimension: XY
#> Bounding box: xmin: 431173.5 ymin: 5337707 xmax: 438554.7 ymax: 5343230
#> Projected CRS: +proj=utm +zone=17 +ellps=GRS80 +towgs84=0,0,0,0,0,0,0 +units=m +no_defs
#> First 10 features:
#> zq90 pzabove2 zsd dist2access geometry
#> 91616 22.80 82.1 5.83 292.12329 POINT (431907.4 5340754)
#> 91943 6.36 48.6 1.58 43.81709 POINT (435474.8 5342194)
#> 91352 16.40 96.4 2.63 126.05873 POINT (435103.8 5338613)
#> 91336 11.20 85.2 2.85 161.26933 POINT (438266.2 5338085)
#> 91403 13.00 56.0 3.91 81.71202 POINT (434548.2 5339073)
#> 92045 15.90 97.1 4.23 112.09092 POINT (434740.9 5342873)
#> 91983 8.09 69.7 2.11 101.80685 POINT (435893.3 5342352)
#> 91438 8.34 64.1 2.05 313.60057 POINT (435563.5 5339169)
#> 91869 4.88 31.3 1.08 27.17280 POINT (434637.8 5341879)
#> 91459 20.20 93.7 3.87 558.16155 POINT (433793.7 5339553)Finally, should the user wish to further constrain the sample based
on access like other sampling approaches in
sgsR that is also possible.
#--- ensure access and existing are in the same CRS ---#
sf::st_crs(existing) <- sf::st_crs(access)
#--- sub sample using ---#
sample_existing(
existing = existing, # our existing sample
nSamp = 300, # desired sample size
raster = dist, # include mraster metrics to guide sampling of existing
cost = 4, # either provide the index (band number) or the name of the cost layer
access = access, # roads layer
buff_inner = 50, # inner buffer - no sample units within this distance from road
buff_outer = 300, # outer buffer - no sample units further than this distance from road
plot = TRUE
) # plot
#> Simple feature collection with 300 features and 4 fields
#> Geometry type: POINT
#> Dimension: XY
#> Bounding box: xmin: 431118.8 ymin: 5337708 xmax: 438534.1 ymax: 5343237
#> Projected CRS: +proj=utm +zone=17 +ellps=GRS80 +towgs84=0,0,0,0,0,0,0 +units=m +no_defs
#> First 10 features:
#> zq90 pzabove2 zsd dist2access geometry
#> 91223 13.3 85.1 3.55 94.42520 POINT (436434.5 5337872)
#> 91497 11.0 57.4 3.03 64.11720 POINT (432806.2 5341666)
#> 91375 18.2 86.0 5.01 175.56188 POINT (432860.9 5340253)
#> 91380 24.1 96.2 5.75 129.37500 POINT (435049.1 5340026)
#> 91405 18.4 91.8 3.46 185.19462 POINT (438252.7 5339896)
#> 91428 14.6 90.7 3.18 127.53129 POINT (432524.8 5340891)
#> 91263 14.8 88.5 3.07 133.71485 POINT (434507 5338675)
#> 91617 17.4 78.9 4.96 127.12217 POINT (438081.6 5342125)
#> 91558 14.4 94.5 3.30 96.50192 POINT (434658.4 5342078)
#> 91675 16.0 35.7 4.63 196.71355 POINT (437169.3 5343024)TIP!
The greater constraints we add to sampling, the less likely we will have strong correlations between the population and sample, so its always important to understand these limitations and plan accordingly.
sample_existing(type = "balanced")
When type = "balanced" users can define all parameters
that are found within sample_balanced(). This means that
one can change the algorithm, p etc.
sample_existing(existing = e, nSamp = 300, type = "balanced")
#> Simple feature collection with 300 features and 3 fields
#> Geometry type: POINT
#> Dimension: XY
#> Bounding box: xmin: 431111.7 ymin: 5337701 xmax: 438547.5 ymax: 5343237
#> Projected CRS: UTM Zone 17, Northern Hemisphere
#> First 10 features:
#> zq90 pzabove2 zsd geometry
#> 4 15.0 95.8 2.87 POINT (431797.2 5337749)
#> 5 21.2 92.8 5.10 POINT (431996.1 5337729)
#> 6 17.6 81.5 4.74 POINT (432195.1 5337708)
#> 14 13.9 94.7 3.15 POINT (432613.5 5337866)
#> 19 17.0 97.6 3.68 POINT (434006.1 5337722)
#> 20 11.0 85.8 2.83 POINT (434205 5337701)
#> 22 19.3 94.2 3.97 POINT (431440.5 5338188)
#> 27 19.5 93.6 2.36 POINT (432435.2 5338085)
#> 28 13.6 92.2 3.12 POINT (432634.2 5338065)
#> 31 25.3 93.4 6.14 POINT (433231 5338003)
sample_existing(existing = e, nSamp = 300, type = "balanced", algorithm = "lcube")
#> Simple feature collection with 300 features and 3 fields
#> Geometry type: POINT
#> Dimension: XY
#> Bounding box: xmin: 431132.3 ymin: 5337769 xmax: 438554.7 ymax: 5343196
#> Projected CRS: UTM Zone 17, Northern Hemisphere
#> First 10 features:
#> zq90 pzabove2 zsd geometry
#> 1 11.7 86.9 3.25 POINT (431200.4 5337811)
#> 2 18.1 94.2 3.97 POINT (431399.3 5337791)
#> 7 21.5 94.6 4.34 POINT (431221 5338010)
#> 9 16.7 87.8 4.83 POINT (431618.9 5337969)
#> 12 14.9 91.5 3.92 POINT (432215.7 5337907)
#> 15 22.2 89.8 6.86 POINT (432812.5 5337845)
#> 16 19.7 93.1 4.81 POINT (433011.4 5337825)
#> 17 25.3 90.6 6.88 POINT (433210.4 5337804)
#> 27 19.5 93.6 2.36 POINT (432435.2 5338085)
#> 28 13.6 92.2 3.12 POINT (432634.2 5338065)
sample_existing(type = "srs")
The simplest, type = srs, randomly selects sample
units.
sample_existing(existing = e, nSamp = 300, type = "srs")
#> Simple feature collection with 300 features and 3 fields
#> Geometry type: POINT
#> Dimension: XY
#> Bounding box: xmin: 431186.9 ymin: 5337708 xmax: 438554.7 ymax: 5343223
#> Projected CRS: UTM Zone 17, Northern Hemisphere
#> First 10 features:
#> zq90 pzabove2 zsd geometry
#> 1 19.90 89.3 5.67 POINT (436482.9 5340280)
#> 2 21.20 88.3 5.56 POINT (432894.9 5338641)
#> 3 14.50 86.3 3.71 POINT (432099.2 5338723)
#> 4 15.70 84.5 3.10 POINT (433279.3 5340411)
#> 5 11.60 93.4 1.78 POINT (435021.4 5337817)
#> 6 17.00 97.6 3.68 POINT (434006.1 5337722)
#> 7 7.64 39.6 1.98 POINT (437511.7 5338565)
#> 8 6.03 25.6 1.54 POINT (435454.2 5341995)
#> 9 25.30 93.4 6.14 POINT (433231 5338003)
#> 10 3.23 9.2 0.64 POINT (434157.5 5341124)
sample_existing(type = "strat")
When type = "strat", existing must have an
attribute named strata (just like how
sample_strat() requires a strata layer). If it
doesnt exist you will get an error. Lets define an sraster
so that we are compliant.
sraster <- strat_kmeans(mraster = mraster, nStrata = 4)
e_strata <- extract_strata(sraster = sraster, existing = e)When we do have a strata attribute, the function works very much the
same as sample_strat() in that is allows the user to define
the allocation method ("prop" - defaults,
"optim", "manual", "equal").
#--- proportional stratified sampling of existing ---#
sample_existing(existing = e_strata, nSamp = 300, type = "strat", allocation = "prop")
#> Simple feature collection with 300 features and 4 fields
#> Geometry type: POINT
#> Dimension: XY
#> Bounding box: xmin: 431104.5 ymin: 5337714 xmax: 438534.1 ymax: 5343209
#> Projected CRS: UTM Zone 17, Northern Hemisphere
#> First 10 features:
#> strata zq90 pzabove2 zsd geometry
#> 1 2 6.76 70.4 1.52 POINT (436873.6 5338229)
#> 2 2 9.59 87.2 2.44 POINT (436997.3 5339422)
#> 3 2 12.10 82.9 3.03 POINT (431729.1 5340974)
#> 4 2 10.10 64.3 3.00 POINT (433759.6 5341165)
#> 5 2 12.80 87.9 2.82 POINT (434521.3 5342695)
#> 6 2 6.04 62.1 1.31 POINT (434164.7 5343134)
#> 7 2 11.60 66.6 3.11 POINT (432106.3 5340733)
#> 8 2 11.00 80.1 2.95 POINT (436880.8 5340239)
#> 9 2 9.22 52.6 2.44 POINT (434699.7 5342475)
#> 10 2 8.34 64.1 2.05 POINT (435563.5 5339169)TIP!
Remember that when allocation = "equal", the
nSamp value will be allocated for each strata.
We get 400 sample units in our output below because we have 4 strata
and nSamp = 100.
#--- equal stratified sampling of existing ---#
sample_existing(existing = e_strata, nSamp = 100, type = "strat", allocation = "equal")
#> Simple feature collection with 400 features and 4 fields
#> Geometry type: POINT
#> Dimension: XY
#> Bounding box: xmin: 431104.5 ymin: 5337714 xmax: 438554.7 ymax: 5343237
#> Projected CRS: UTM Zone 17, Northern Hemisphere
#> First 10 features:
#> strata zq90 pzabove2 zsd geometry
#> 1 2 13.00 55.3 3.67 POINT (433121.6 5340829)
#> 2 2 9.80 98.6 1.97 POINT (436832.4 5337831)
#> 3 2 11.80 73.9 2.71 POINT (432511.4 5342702)
#> 4 2 12.40 49.4 2.83 POINT (436174.6 5343127)
#> 5 2 6.04 62.1 1.31 POINT (434164.7 5343134)
#> 6 2 9.94 62.0 2.77 POINT (437532.3 5338764)
#> 7 2 9.90 72.4 2.63 POINT (436036.7 5337913)
#> 8 2 13.00 56.0 3.91 POINT (434548.2 5339073)
#> 9 2 10.60 93.6 2.57 POINT (431262.2 5338408)
#> 10 2 14.90 19.1 4.46 POINT (434322.4 5342716)
#--- manual stratified sampling of existing with user defined weights ---#
s <- sample_existing(existing = e_strata, nSamp = 100, type = "strat", allocation = "manual", weights = c(0.2, 0.6, 0.1, 0.1))We can check the proportion of samples from each strata with:
#--- check proportions match weights ---#
table(s$strata) / 100
#>
#> 1 2 3 4
#> 0.2 0.6 0.1 0.1Finally, type = "optim allows for the user to define a
raster metric to be used to optimize within strata
variances.
#--- manual stratified sampling of existing with user defined weights ---#
sample_existing(existing = e_strata, nSamp = 100, type = "strat", allocation = "optim", raster = mraster, metric = "zq90")
#> Simple feature collection with 99 features and 4 fields
#> Geometry type: POINT
#> Dimension: XY
#> Bounding box: xmin: 431173.5 ymin: 5337770 xmax: 438534.1 ymax: 5343072
#> Projected CRS: UTM Zone 17, Northern Hemisphere
#> First 10 features:
#> strata zq90 pzabove2 zsd geometry
#> 1 2 11.30 65.9 3.07 POINT (436353 5342907)
#> 2 2 9.78 84.2 2.46 POINT (438534.1 5340671)
#> 3 2 11.70 73.4 2.68 POINT (434088.5 5338517)
#> 4 2 12.60 71.3 3.35 POINT (437937.3 5340732)
#> 5 2 10.60 93.6 2.57 POINT (431262.2 5338408)
#> 6 2 9.18 53.8 2.40 POINT (436023.2 5339724)
#> 7 2 10.70 54.5 2.64 POINT (431194.1 5341632)
#> 8 2 12.80 77.8 2.96 POINT (432305.3 5340713)
#> 9 2 11.20 61.6 3.11 POINT (437704.3 5342365)
#> 10 2 10.30 72.7 2.50 POINT (436531.3 5342688)We see from the output that we get 300 sample units that are a
sub-sample of existing. The plotted output shows cumulative
frequency distributions of the population (all existing
samples) and the sub-sample (the 300 samples we requested).